
Face recognition in unconstrained environments such as surveillance, video, and web imagery must contend with extreme variation in pose, blur, illumination, and occlusion, where conventional visual quality metrics fail to predict whether inputs are truly recognizable to the deployed encoder. Existing FIQA methods typically rely on visual heuristics, curated annotations, or computationally intensive generative pipelines, leaving their predictions detached from the encoder's decision geometry. We introduce TransFIRA (Transfer Learning for Face Image Recognizability Assessment), a lightweight and annotation-free framework that grounds recognizability directly in embedding space.
TransFIRA delivers three advances:
Experiments confirm state-of-the-art results on faces, strong performance on body recognition, and robustness under cross-dataset shifts. Together, these contributions establish TransFIRA as a unified, geometry-driven framework for recognizability assessment — encoder-specific, accurate, interpretable, and extensible across modalities — significantly advancing FIQA in accuracy, explainability, and scope.
TransFIRA adapts a pretrained encoder to predict recognizability—the likelihood that an image will be correctly identified—directly from the encoder’s embedding geometry.
The framework consists of three stages:
Recognizability is defined entirely within the embedding space of the chosen encoder, ensuring that it reflects the model’s actual discrimination ability rather than superficial factors such as blur, illumination, or occlusion. For each image \(x_i\) with embedding \(z_i = \phi(x_i)\), we compute a set of class-center similarities that quantify how well the embedding aligns with its identity.
The Class Center Angular Similarity (CCS) measures how closely an embedding aligns with the center of its own class:
\( CCS_{x_i} = \frac{z_i^\top \mu_{y_i}}{\|z_i\|_2 \, \|\mu_{y_i}\|_2} \)
The Nearest Nonmatch Class Center Angular Similarity (NNCCS) measures its similarity to the most confusable impostor class:
\( NNCCS_{x_i} = \max_{\,j \neq y_i} \frac{z_i^\top \mu_j}{\|z_i\|_2 \, \|\mu_j\|_2} \)
Their difference defines the Class Center Angular Separation (CCAS):
\( CCAS_{x_i} = CCS_{x_i} - NNCCS_{x_i} \)
A natural cutoff emerges at CCAS > 0, indicating that an embedding is closer to its own class center than to any impostor. This provides a principled, parameter-free definition of recognizability grounded in the encoder’s decision geometry.
To predict recognizability directly from images, TransFIRA extends a pretrained backbone with a lightweight recognizability prediction head implemented as a small MLP. The network outputs predicted scores for both CCS and CCAS:
\( \hat{\mathbf{r}}_i = [\hat{CCS}_{x_i},\, \hat{CCAS}_{x_i}]^\top = h_\psi(\phi(x_i)) \)
Training is performed end-to-end with mean squared error against ground-truth recognizability labels derived from the encoder itself. Fine-tuning both the backbone and head ensures recognizability remains encoder-specific, efficient to train, and fully aligned with the model’s internal representation.
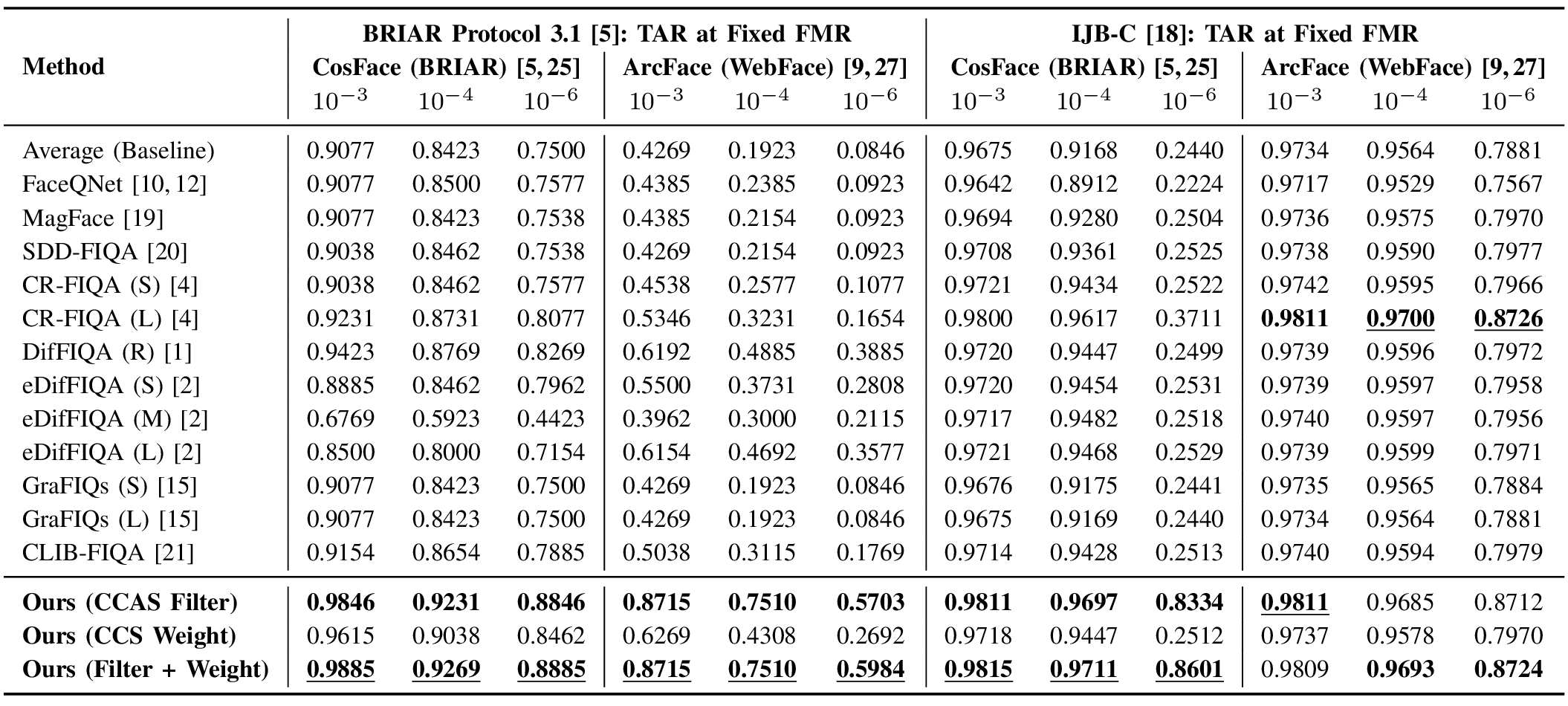
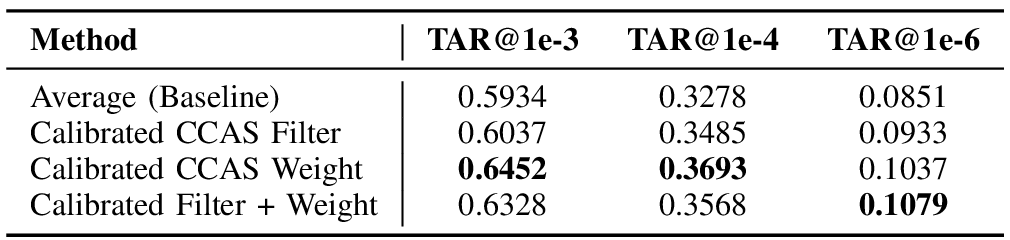
In template-based recognition benchmarks such as BRIAR and IJB-C, multiple images of a subject are combined into a single representation. TransFIRA uses predicted recognizability scores to guide this aggregation through two complementary steps:
These operations form a recognizability-informed aggregation strategy that is both interpretable and parameter-free. Filtering ensures only geometrically valid samples are included, while weighting strengthens alignment with the class center, jointly improving accuracy and explainability.
@article{Tu2025TransFIRA,
author = {Tu, Allen and Narayan, Kartik and Gleason, Joshua and Xu, Jennifer and Meyn, Matthew and Goldstein, Tom and Patel, Vishal M.},
title = {TransFIRA: Transfer Learning for Face Image Recognizability Assessment},
journal = {arXiv preprint arXiv:2510.06353},
year = {2025},
url = {https://transfira.github.io/}
}